
TensorFlowを用いた年齢性別判定システムの構築
TensorFlowを用いた年齢性別判定システムの構築を説明する。
目次
構築手順
1.はじめに
2012年、物体の認識率を競うILSVRCにおいて、ジェフリー・ヒントン率いる研究チームがそれまで頭打ちとなっていた画像認識率の飛躍的な改善を成し遂げた。彼らの用いた学習方法こそがディープラーニングだ。 ※(狭義では特に4層以上の)多層ニューラルネットワークによる機械学習の手法をディープラーニングと言う。
この成果に目を付けた米大手企業がこぞってディープラーニング研究に乗り出し、そのうねりは第3次人工知能ブームとも呼ばれる社会現象を巻き起こしている。
そこで、ディープラーニング研究のため、人の顔画像をインプットにして性別と年齢を判定させる「年齢性別判定システム」を作成した。
2.TensorFlow(テンソルフロー)の説明
TensorFlowはGoogleによって開発された機械学習のためのオープンソースライブラリだ。
機械学習ライブラリは下記に示す通り数多く存在するが、トレンド性、利用者数、インターネット上の情報量などを鑑みて、TensorFlowを採用した。
[表:主な機械学習ライブラリ(2016年時点)]
| 対応OS | 言語 | ライセンス | GPU対応 | 開発元 | |
| TensorFlow | Ubuntu、MacOS | Python、C++ | Apache2.0 | ○ | |
| Chainer | Ubuntu、CentOS、MacOS | Python | MT license | ○ | preferred Networks |
| Caffe | Windows、Ubuntu、CentOS、MacOS | C++ | BSD2-clause | ○ | Barkeley Vision and Leaning Center |
| Theano | Windows、MacOS | Python | OpenSource | ○ | モントリオール大学 |
| Torch | Ubuntu、MacOS | Lue | BSD License | ○ | Ronan Collebert氏中心のグループ |
| scikit-lean | Windows、Ubuntu、MacOS | Python | BSD License | × | David Cournapeau |
| PyML | Linux、MacOS | Python | GNU Library,LGPLv2 | ? | AsaBen-Hur |
| Pylearn2 | Linux、MacOS | Python | BSD3-clause | ○ | LISA Lab |
| PyBrain | Linux、MacOS | Python | BSD License | × | project of PostDocs |
3.開発環境
使用した開発環境は以下の通り。
※インストール手順は割愛
◎ Ubuntu 16.04.1 LTS
◎ Python 2.7.12
◎ httplib2 0.10.3
◎ OpenCV 2.4.9.1
◎ TensorFlow 0.11
◎ Numpy 1.11.2
◎ Flask 0.11.1
◎ uWSGI 2.0.14
4.学習フロー
機械学習の学習フローの概要は下記の通り。
- 学習データの準備
- 特徴ベクトルへの変換
- 学習させる
- 評価する
1.学習データの準備
ニューラルネットワークは「教師あり学習」のため、インプットとなる個別のデータに対して「正解」を事前に提示する必要がある。
また、『「教師なし学習」を併用し教師データを作る』など工夫が必要。
※当システムでのデータ収集方法は「crawlerで学習データを収集する」項参照。
2.特徴ベクトルへの変換
「特徴抽出」などと呼ばれる工程で、機械学習において最も重要な工程。
学習データの何を「特徴」としてベクトル化するのかが学習の精度を決める。
特徴ベクトルというのは多次元配列のこと。
学習データを決まったフォーマットの多次元配列に変換することで、様々な学習手法を同列に適用可能になる。
この工程内容は下記の通り。
◎ 特徴ベクトルフォーマットの決定
◎ 学習データ⇒特徴ベクトルへの変換
※当システムでの特徴ベクトルへの変換方法は「収集した画像データを入力フォーマットに加工する」項参照
3.学習させる
学習をさせるためには下記準備が必要。
①モデルとして何を採用するかを決める
モデルは日進月歩のためインターネット上に日々新しいモデルが公開されている。機械学習ライブラリにも典型的なモデルがサンプルとしてついてきているが、学習するお題によってはモデルにも得手不得手があるため、最適なモデルの選定が必要。
②モデルに設定するメタパラメータの内容を決める
準備が整い次第、作成した特徴ベクトルをライブラリに投入して計算を繰り返させる。
※実際には、「学習させる⇒評価する」を繰り返しながら調整していく。
※当システムでの使用モデル等は「学習させる」項参照
4.評価する
代表的な評価手法は「交差検定(※1)」という手法。
学習データとテストデータを入れ替えながら、「学習⇒評価」を繰り返すことで、より精度の高い評価結果が得られる。
※1 データを分割しその一部分で学習し、残りの部分をテストデータとして評価に利用する手法です。
準備するデータの注意事項は下記の通り。
○学習データとテストデータに同じデータがあると精度が上がる
×学習データとテストデータでデータの傾向が違う(データを取得した時の背景が異なるなど)
5.年齢性別判定システムの学習フロー
年齢性別判定システムの学習フローの概要は下記の通り。
- crawlerで学習データを収集する
- 収集した画像データを入力フォーマットに加工する
- 学習させる
- 評価する
- システムに組み込む
1.crawlerで学習データを収集する
当システムでは大量の顔画像データが必要なため、Google Custom Search APIを使って画像収集することにした。
検索ワードと取得数を引数に与え、APIから画像のURLを抽出しそれを個別にダウンロードしてくるスクリプトを作成した。
検索ワードがそのまま教師データの「正解」を意味するようにした。
◎ (参考)Google Custom Search APIを使って画像収集
注意事項は下記の通り。
◎ Google Custome Search APIには制限があり、無償利用の範囲では一日100リクエストしか流せない。
◎ 検索結果も100位までしか取得できない。
◎ キーワードとはマッチしない画像も含まれているため、人力で取り除いてく必要がある。
2.収集した画像データを入力フォーマットに加工する
収集した画像には「顔」が写ってはいるが、写り方が様々であり、そのまま入力しても特徴を捉えることができない。
そこで画像処理ライブラリOpenCVを使用し、画像から「顔」の部分だけを抽出したものを特徴ベクトルとする。
※OpenCVの使用方法は割愛。
◎ OpenCV公式
3.学習させる
①インプットデータを作成する。
TensorFlowに提供されている機能の「特徴ベクトルに変換する機能」を利用し、インプットデータを作成する。
◎ TensorFlow Programmer’s Guide – Reading data
インプットデータを生成するには、以下のフォーマットのCSVファイルを準備する。
<画像データのファイル, 教師情報>②教師データの設定
教師情報は判定したい正解を数値化したものなので、今回は以下の8カテゴリのデータを「教師データ」に設定した。
| 1 | male adult |
| 2 | male middle |
| 3 | male elder |
| 4 | female youth |
| 5 | female adult |
| 6 | female middle |
| 7 | female elder |
③モデルの選定
モデルはTensorFlowの「CIFAR-10」という画像認識サンプルで使われているCNNを使用。
◎ 入力 (48×48 3chカラー)
◎ 畳み込み層1
◎ プーリング層1
◎ 畳み込み層2
◎ プーリング層2
◎ 全結合層1
◎ 全結合層2
④メタパラメータの内容決め
TensorFlowに提供されている「データ拡張(※)」を使用すれば少なめのデータでも一定の学習が可能。
※データ拡張とは・・・
わざとノイズを入れたり、コントラストを調整したり、画像を拡大縮小、回転、平行移動などして、同じ画像を水増しして学習させること。
ただ水増しするだけでなく、微妙に違う画像を”同じモノ”と認識させる点が重要。
⑤学習開始
⑤学習開始
学習データの中から60枚ずつをランダムに取り出し、一つのミニバッチとして「学習→モデルの更新(パラメータの調整)」を繰り返す。今回は3800回ほど学習させた。※通常1000~数万回この工程を繰り返す。
以下が各ステップごとの精度(正解率)とロス(誤差関数の値)の結果。※学習時間は5~6時間
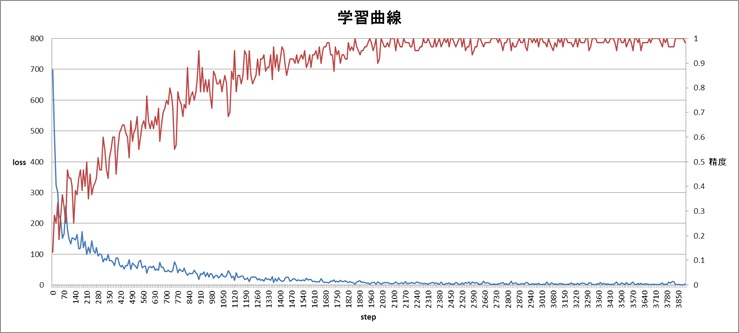
入力データが大きすぎたりモデルのメタパラメータが適切でなかったりすると、学習は発散してしまう。
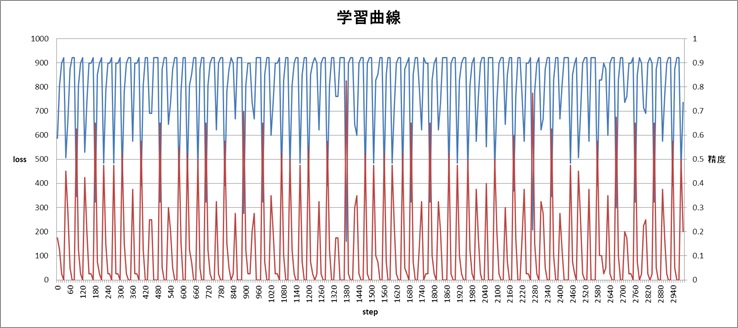
4.評価する
本来ならば、学習させたモデルをテストデータを使って評価するが、テストデータを用意できるほど学習データを集められなかったため割愛。
5.システムに組み込む
Webアプリ上の枠に判別対象の顔画像をドラッグ&ドロップすると、8カテゴリのどこに該当するかを判定してくれる「年齢性別判定システム」が完成した。
○使用方法
システム上で入力データから特徴ベクトルを生成し、学習したモデルで処理させ判定結果を得る。
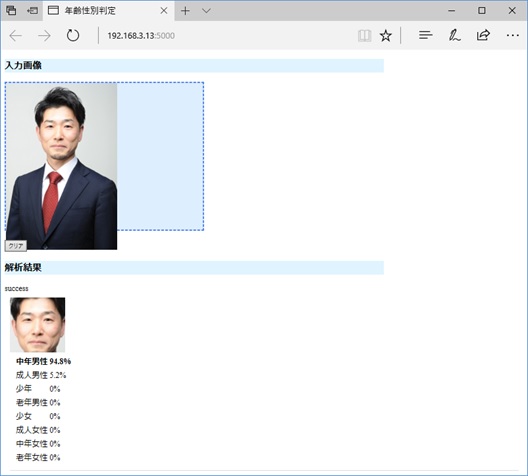
6.年齢性別判定システム
上記手順で作成した年齢性別判定システム
年齢性別判定システム
7.今後の課題
スクレイピング
学習データの準備にかなり手間取ったため、スクレイピングについては大いに改良の余地あり。
今回用意できたデータは8カテゴリの計1,800枚。しかし、カテゴリで用意できた枚数にバラつきがあり、学習不足のため判別されないカテゴリが見受けられた。
また、検索ワードから教師情報を決定したが中には誤った教師データも含まれており、中には誤った教師データも含まれており、気づいた誤データは除去したが、除去しきれていない可能性もある。
ニューラルネットワークについての理解
モデルのチューニングを行うためには、多層ニューラルネットワークがどのようにして「学習」しているのかを理解する必要がある。
「どうして学習が発散してしまうのか。収束させるためには何が必要なのか。」はニューラルネットワーク理論を理解したうえで試行錯誤する必要がある。
別のモデルも試してみる
ニューラルネットワークの理解を進めるためにも、別のモデルでの学習精度の違いも確認したい。
どのようなモデルだと精度が上がるのかが分かれば、より深いニューラルネットワークの理解に繋がる。
オンライン学習
システムとして運用しながら学習させるというのは、一つの手段として有用。
今回作った年齢性別判定システムは、判別用に投入された画像データをモデルの更新に利用する仕組みを備えていないため、改善の余地あり。