
日本語形態素解析エンジンを利用した『トレンドキーワード分析システム』
日本語形態素解析エンジンを利用した『トレンドキーワード分析システム』を説明する。
目次
Hadoopインストール手順
1.概要
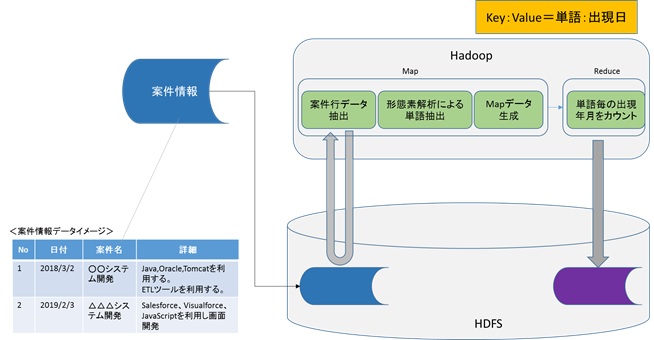
オープンソースの日本語形態素解析エンジンKuromojiと大量データ処理基盤としてHadoop(MapReduce)を利用して『トレンドキーワード分析システム』を開発する。
<概要図>
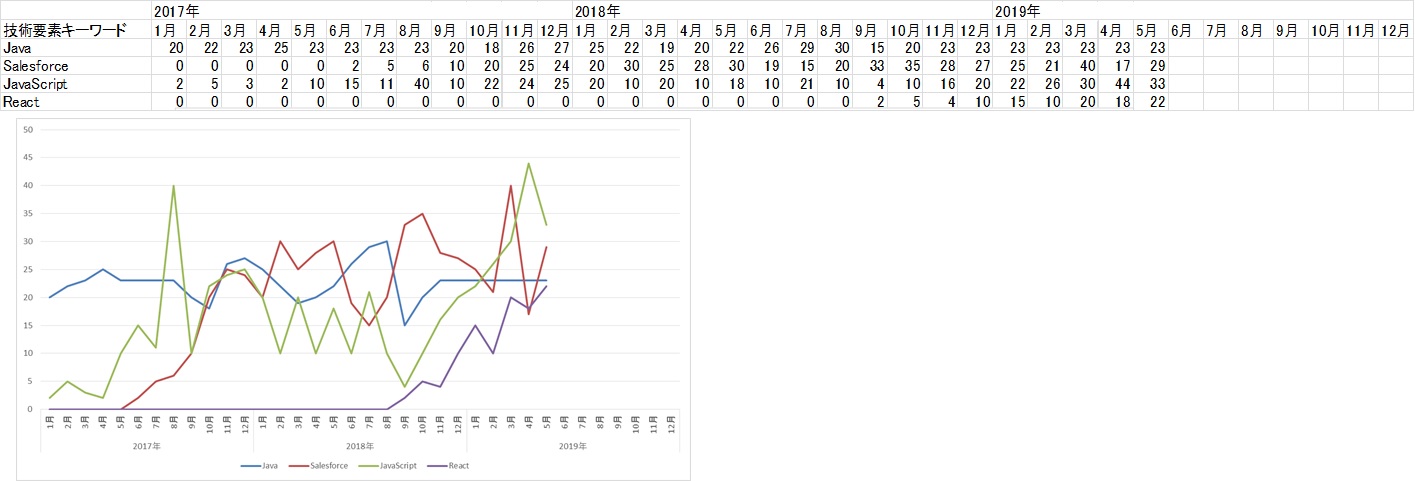
<アウトプットイメージ>
2.説明
オープンソースの日本語形態素解析エンジンKuromojiはJavaで実装されており、ライセンス「Apache v2 License」として提供されている。
独自単語の辞書登録も可能であるため、単語分割の精度を上げる事ができる。
◎ atilika
◎ kuromojiのソースコード
案件情報の記載がある大量テキストデータから頻出キーワードと日付をグラフ化し頻出傾向を特定する。
技術キーワードと出現タイミングを「<アウトプットイメージ>」のように出力するもの。
3.開発手順
Eclipseで空のmavenプロジェクトを作成する。
「Create a Maven project」リンク押下
「Create a simple project(skip archetype selection)」を選択
「Group Id」と「Artifact Id」を入力する
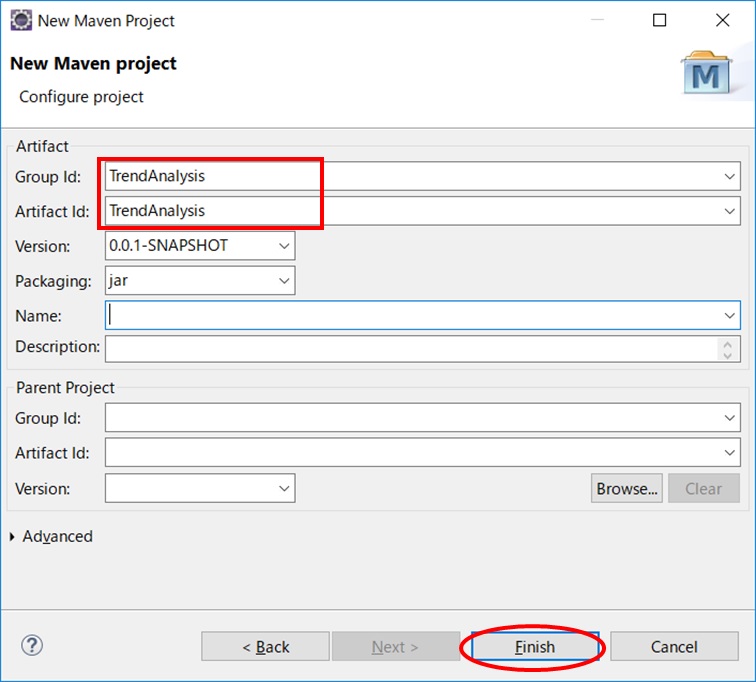
pom.xmlファイルを編集する
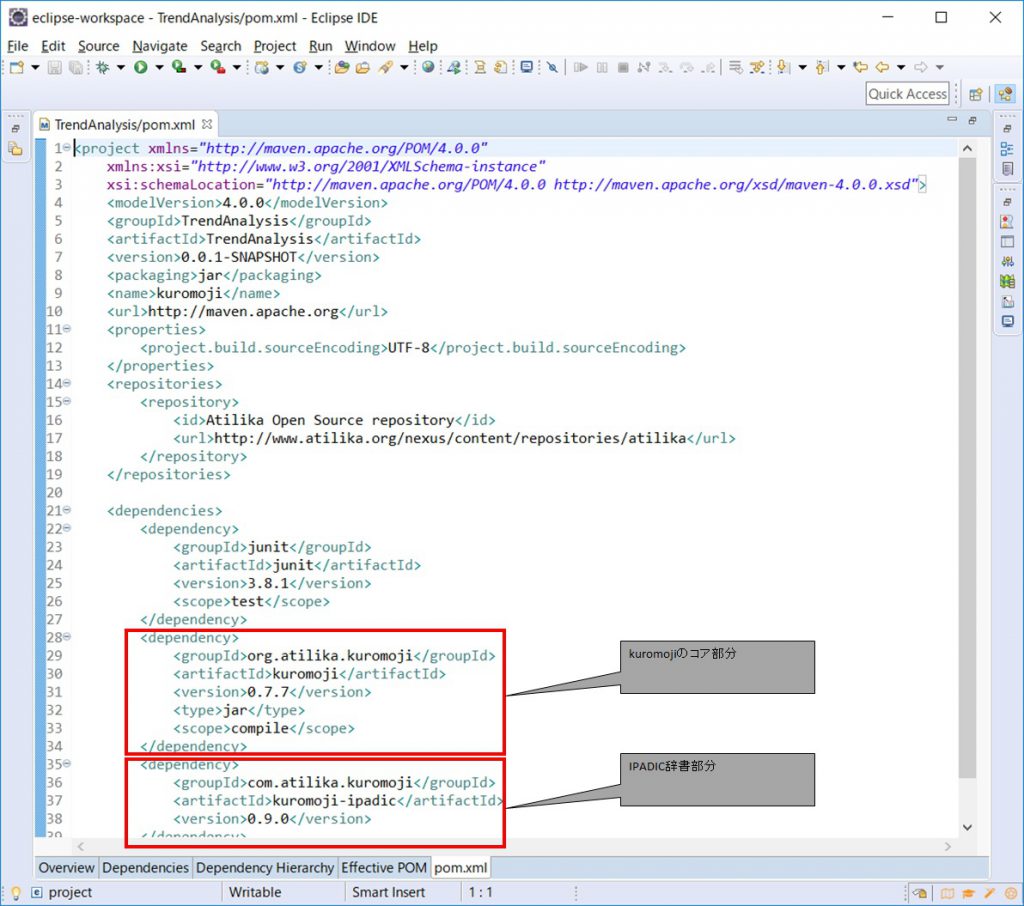
ipadic利用
ipadicも利用可能とする
pom.xmlを編集しkuromoji関連ライブラリダウンロードしipadicも利用可能とする。
※本系サイトの説明通り「kuromoji-ipadic」辞書を利用
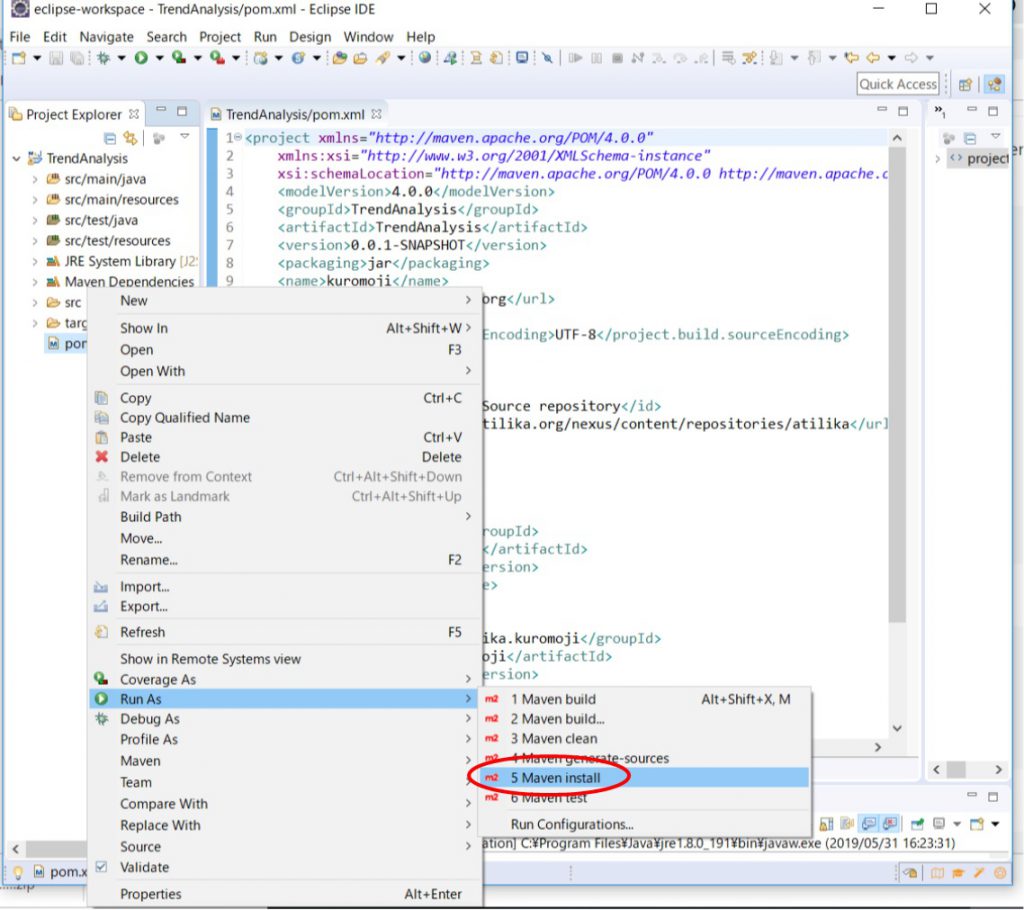
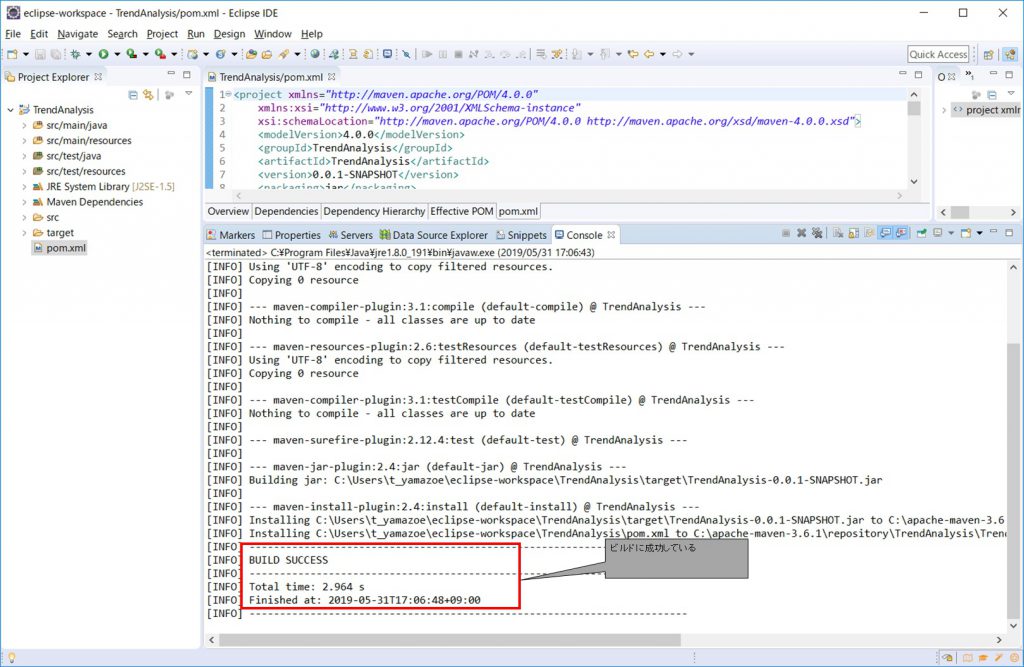
Mavenを実行
ビルド状況を確認
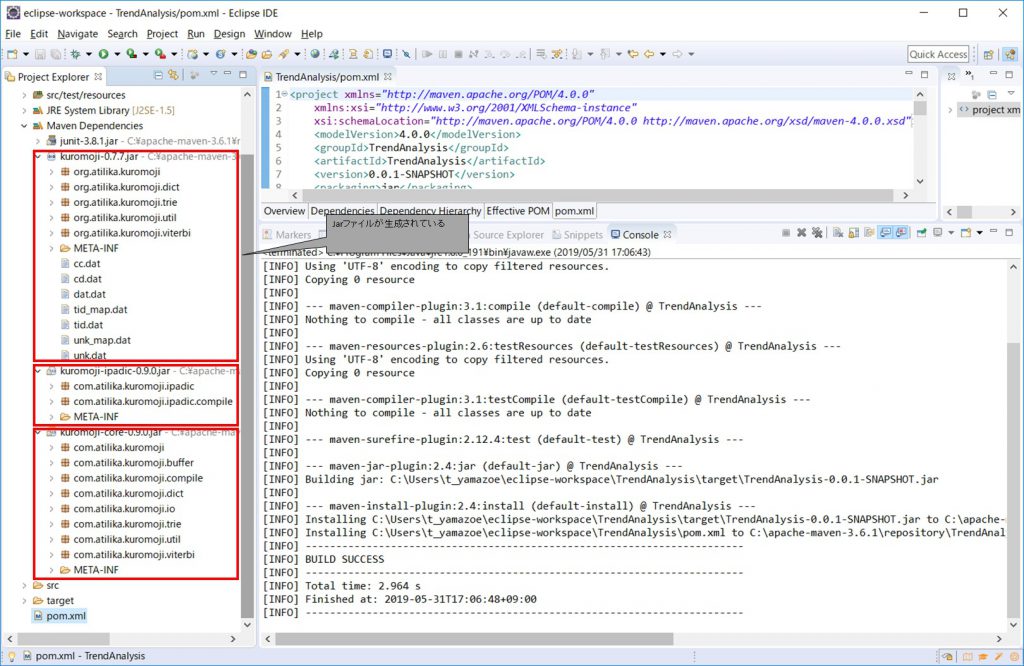
ライブラリが生成完了
ライブラリが生成された状態。※コアライブラリとIPADICのライブラリ
プログラム実行
プログラムを作成し実行。※Java単体での実行が確認できる
「C://temp/sample.txt」ファイルを読み込み行毎にトークン分解できている様子が分かる

<<Hadoopでの処理を実装中>>
大量テキストデータをHadoop(MapReduce)で処理する事で水平負荷分散を可能にするもの。